


In this article we will have an overview of what are our options for storing tokens on public clients such as a Single Page Application (SPA). We will consider different things mostly in the context of access tokens and OAuth.
Token-Aware Client
Web Storage
I believe that the majority of us, at some point in our careers, used Web Storage API to store some data in the browser.
The API is straightforward and saving and retrieving data is as convenient as it gets.
There are two types of Web Storage - localStorage and sessionStorage.
They function in an extremely similar way but the key differences are:
Data stored in sessionStorage is available until the browser is closed, or until the tab is closed - for the duration of the page session*
Data stored in localStorage is persisted until removed explicitly
*If you open the page in a new tab by duplicating the current tab then the data from sessionStorage will not be lost.
If you open the page in a new tab explicitly, by opening a new empty tab and then pasting the URL of the page and hitting Enter, the data from sessionStorage will be lost.
I thought this was an interesting thing to mention.
Even though storing tokens in localStorage and sessionStorage is convenient there is a problem - both things are vulnerable to Cross-Site Scripting (XSS) software attacks.
If an attacker somehow manages to inject a malicious JavaScript code, he/she can easily get hold of our token, send it to himself/herself, and then access protected resources on our behalf, because any data in localStorage or sessionStorage is accessible via JavaScript.
What about IndexedDB?
IndexedDB
IndexedDB is a really powerful feature of modern browsers and is meant for storing larger amounts of structured or even binary data on the client-side.
The operations using IndexedDB are asynchronous, so it might feel like a more attractive option compared to Web Storage whose operations are synchronous.
However, due to the primary intent of IndexedDB, which is storing larger amounts of structured data, as well as the complexity of the API, I feel like it might be too much for the sake of storing tokens.
The XSS vulnerability still stands, even with IndexedDB.
Another option is to store tokens in HTTP cookies.
HTTP Cookies
This is the option in case of server-side rendering because the page is being assembled on the server and then served to the client so at the time of the assembling we can not use Web Storage to store the token because it is a browser feature.
A thing to consider is that the maximum size of a cookie is 4KB, so if our token somehow exceeds this limit then cookies might not be a way to go.
I am not completely sure if this is the case for all browsers because the RFC 6265 specification clearly states that the user agents SHOULD provide the size of at least 4096 bytes per cookie.
Does storing tokens in the cookies eliminate the threat of XSS? Not exactly.
If we are using httpOnly cookies then they are not accessible via JavaScript, which is an advantage over localStorage, sessionStorage, or IndexedDB.
However, if an XSS attack occurs, the attacker can still send an HTTP request to the server and the cookies will also be sent - for example by injecting a code snippet that uses fetch().
In regards to XSS, cookies with the httpOnly flag are safer in terms that the attacker can not directly read the content of the token, but he/she can still send the token as part of the attack.
Cookies can be sent across different domains, so it opens the possibility of Cross-Site Request Forgery (CSRF) attacks.
No matter where a request to a particular domain is initiated, the browser attaches the cookies that are related to that domain in the request.
For that reason, we have to consider implementing anti-CSRF tokens or using the sameSite flag set to strict.
If we are storing tokens in localStorage then we are vulnerable to XSS attacks. If we are storing tokens in httpOnly cookies we are less-vulnerable (not directly vulnerable) to XSS attacks, but we are vulnerable to CSRF attacks.
CSRF related vulnerability, as we already said, can be mitigated by using the sameSite flag set to strict, and possibly by using anti-CSRF tokens.
So which approach should we opt for?
Hybrid Approach
An interesting approach is to store the access token in memory, that is, in a JavaScript variable.
In case that we are using a flow that, in addition to the access token, also returns the refresh token, we can store the refresh token in an httpOnly cookie.
Storing refresh tokens on public clients should generally be avoided, but for the sake of the article let us consider that as well.
Is this approach safe from CSRF?
Theoretically, the attacker could submit a form to the token refresh endpoint, and the new token would be returned, but the attacker can not read the response if he is using an HTML form.
The attacker could, however, make an AJAX request instead, but the CORS policy on the server should prevent requests from unauthorized sites.
Once the user successfully authenticates, the auth server would return the access token in the response body, and the refresh token in a cookie.
The following flags should be associated with the cookie:
- secure - to make sure that the refresh token is being transmitted only via HTTPS
- httpOnly - to prevent the JavaScript code from reading the content of the cookie
- sameSite - set to strict, if possible
Note that adding sameSite with the value strict is possible if the auth server and the site are on the same domain.
In case that they are not, the server needs to implement a proper CORS policy or any other methods to prevent requests from unauthorized sites.
The access token once received on the client should be put into a variable.
However, by having it in a variable it means that we would lose it when refreshing the page or opening the page in different tabs for example.
So if we lose the access token by refreshing the page, opening the page in a new tab, or if it perhaps expires, we can re-obtain it with the refresh token and continue the journey.
Auth0 has the approach for SPA-s where they store the access token in memory - in a variable, and they use Web Workers to handle the transmission and storage of the token.
In case that we can not use Web Workers, Auth0 suggests using JavaScript closures to emulate private methods.
One more approach that we can take, and that can be considered as an additional security measure is that we disassemble our access token into two parts:
- The first part would represent the header and payload and we would store it in the memory
- The second part would represent the signature and we would store it in an httpOnly cookie
With this approach, the JavaScript code never has the access to the full access token.
The API that we are sending a request to, or any intermediary component, would need to assemble the token on its side to validate it.
This is an interesting approach and is probably the safest if there is a need for the client to read some content from the token - to be aware of the token as a whole.
Unfortunately, there is no perfect and completely secure solution.
Event the in-memory storage is vulnerable to XSS.
It is just that getting the token from a variable is less straightforward than getting it from something like localStorage or sessionStorage - from an attacker's perspective.
We can mitigate and even prevent CSRF attacks but it is very challenging to completely eliminate the possibility of XSS attacks.
Token-Unaware Client
The following two approaches take a stand of not providing the access token to clients directly, so they should be considered if the client code never reads the content of an access token - ideally, it should not.
The first one is called The Phantom Token approach.
Phantom Token
The basic idea is to have a pair of an opaque token and a structured token (JWT).
The other terminology that is used for these two types of tokens is a reference token and a self-contained token, respectively.
Opaque token should be a random string and not have any meaning to the resource server, that is, to the API.
It should be used purely as a reference to the “real” token - the JWT access token.
The client should not be aware of the JWT access token, only of the opaque token.
Therefore, even if the client code attempts to read the content of it, it will essentially have nothing to read.
The only way to obtain the JWT access token, which represents the "real token", should be by using the opaque token.
The flow would look like this:
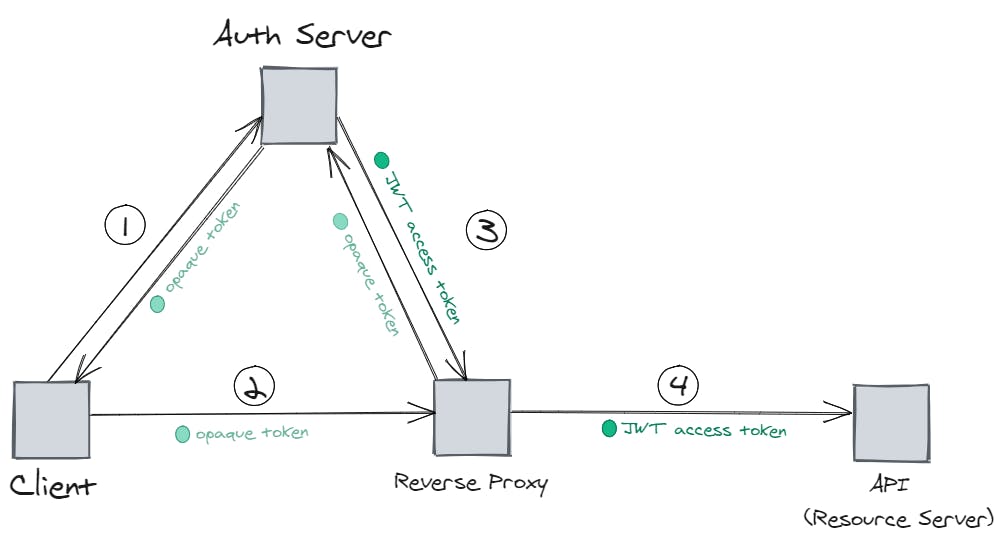
- The client sends a token request to the auth server and the auth server returns an opaque token
- The client sends a request to the API and includes that opaque token in the request
- The reverse proxy sends a request to the token introspection endpoint on the auth server and exchanges the opaque token for a JWT access token
- The reverse proxy then forwards the request including the JWT access token to the API
This approach is good because the client is never aware of the JWT access token and can not extract any data from it - which is good since access tokens are intended for APIs.
Although we said that the opaque token is a random string we could also attach some minimal data to it, such as the validity time of the original token and relevant scopes.
This data could help the reverse proxy make basic authorization operations such as returning Unauthorized in case that the validity time has expired or that scopes are not the ones that the API supports.
We can also leverage the reverse proxy caching mechanisms and cache the JWT access token the very first time it is received.
By doing that we would minimize the number of requests for token exchange.
Let us take a look at the second approach which is called The Split Token approach which is in a way similar to the token splitting technique described before.
Split Token
The Split Token approach is good for scenarios where we do not want to tolerate the potential latency that the Phantom Token approach can introduce since the reverse proxy has to make a token exchange request to the auth server every ~X minutes where X represents the lifetime of the token - in case that we are leveraging the reverse proxy caching mechanism.
In case that we do not have a caching mechanism, every request to the API requires an additional request performed by the reverse proxy - token exchange request.
The other thing that we might not want to tolerate is that JWT access tokens are stored in the cache of the reverse proxy which might theoretically represent a security weakness.
The idea of Split Token is very similar to the idea of the Phantom Token - the client is not aware of the “real” token - JWT access token, only the opaque token.
With this approach, as we will see, the reverse proxy does not need to make a token exchange, and the JWT access token does not have to be cached as a whole.
The client sends a token request to the auth server. Before the auth server sends back a response it splits the JWT token into two parts:
- The signature of the token
- The header and payload of the token
The signature part is sent back to the client and is considered an opaque token.
At the same time, the auth server creates a hash of the signature and sends that hash together with the header and payload part to the reverse proxy.
The reverse proxy caches the header and the payload of the JWT token using the signature hash as the cache key.
When the client sends a request by including the signature of the token, the reverse proxy takes that signature, hashes it, and looks up for the header and payload in the cache.
When the reverse proxy retrieves the header and payload, it can assemble the whole JWT access token, include it in the request, and then forward the request to the API.
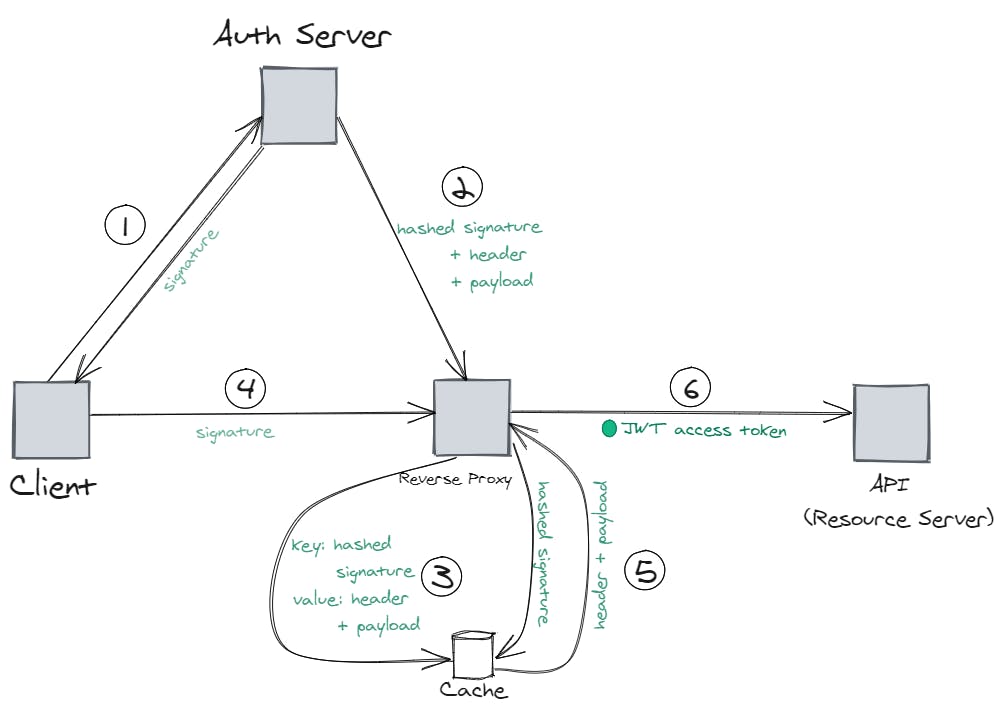
- The client sends a token request and the auth server sends back the signature part of the token
- Simultaneously, the auth server sends a hashed signature as well as the header and payload parts of the token to the reverse proxy
- The reverse proxy caches the header and payload parts by using the hashed signature as the cache key
- The client sends a request to the API and includes the signature part in the request
- The reverse proxy receives the request, hashes the signature, and retrieves the header and payload parts based on the hashed signature. At this point, the reverse proxy has all parts and can assemble the JWT access token.
- The reverse proxy includes the JWT access token in the request and forwards the request to the API
With this approach, there is no need for the reverse proxy to send an additional request to the auth server to exchange tokens.
It is also more secure in terms that the whole JWT access token is not being cached, only the header and payload parts of it.
Even if someone, theoretically, manages to access the cache of the proxy, they will still need the original signature which is stored on the client.
If your architecture is located on Amazon Web Services (AWS) you can use Amazon API Gateway to act as a reverse proxy.
You could implement the pattern above by using Amazon API Gateway and Lambda Authorizer (Custom Lambda Authorizer).
Or in case that you are more of an Azure person, you could accomplish something similar with Azure API Management where you can define a custom external authorizer policy.
Azure API Management External Authorizer
I believe that there are many additional things to be discussed about the idea of safe token storage and that neither solution is perfect, but I wanted to provide an overview of the things that can be considered.