

When talking about relational databases some of the most common names that come up are Microsoft SQL Server, MySQL, and PostgreSQL.
Broadly speaking, what a database represents is an organized set of data that is most commonly stored as a collection of files on the permanent memory. If a database uses the relational model for organizing data, then we are talking about relational databases.
Now, referring to either Microsoft SQL Server, MySQL, or PostgreSQL as a relational database is not fully precise. Strictly speaking, each of these is a relational database management system - RDBMS.
RDBMS is a powerful and complex software system that, we could say, lies between the client that is requesting data and the permanent memory where data is stored physically.
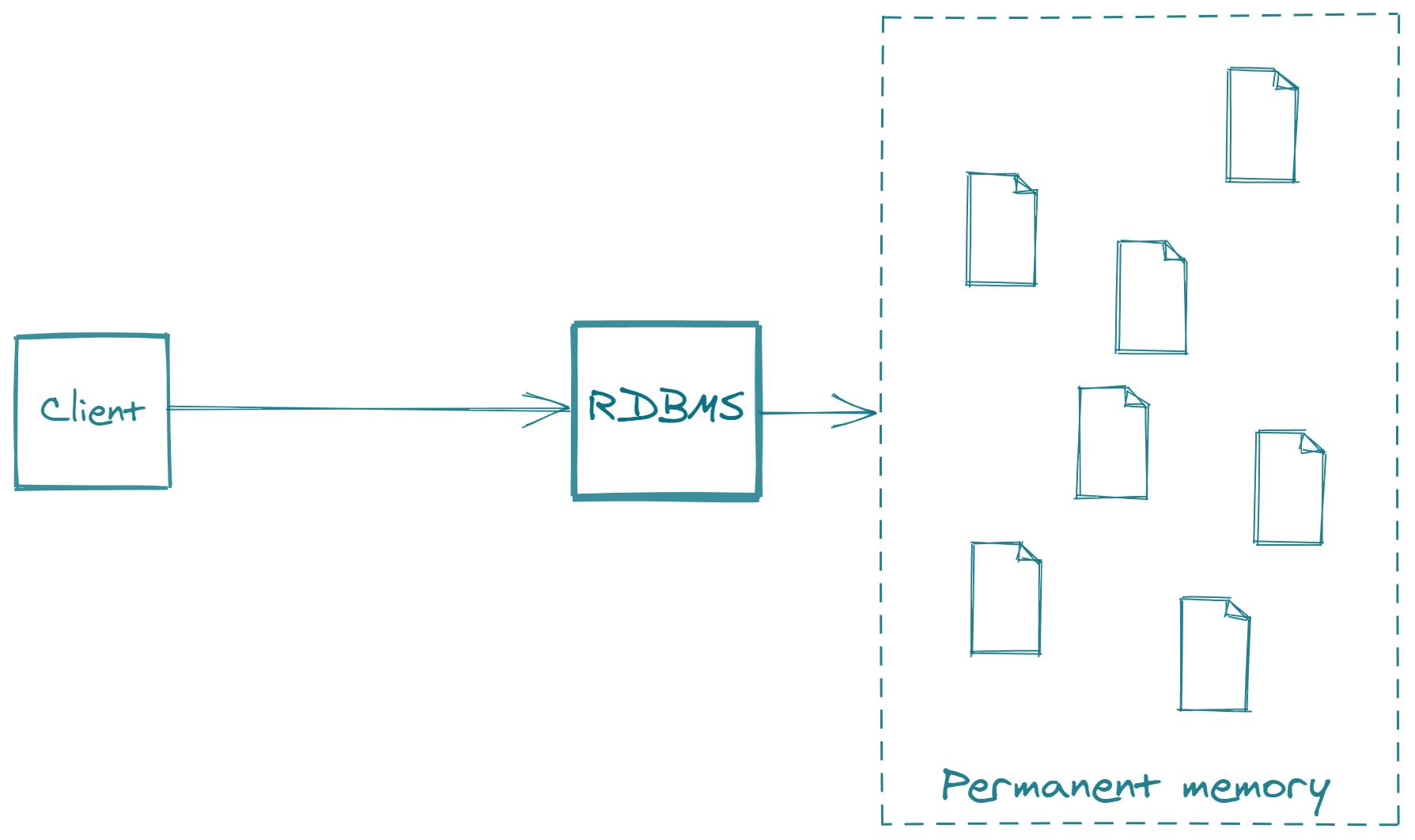
An RDBMS does all the heavy lifting when it comes to working with data.
Some of the key features are:
- Providing Structured Query Language (SQL) that allows us to define the database schema - a blueprint on a logical level of how the data is structured, what the relationships are, and which integrity constraints apply to different pieces of the data, as well as to read and modify the data
- Securing the data and controlling access to it (authentication and authorization)
- Using appropriate structures to provide efficient access to large amounts of data stored on the permanent memory (indexes)
- Caching the data that was recently accessed in the temporary memory in order to provide more efficient future access
- Ensuring that the consistency of the data is maintained in cases of concurrent data access (transactions)
- Recuperation in cases of unwanted software or hardware failures
- Abstracting away the details of the physical data representation which as a result has that the client that is accessing the data is not affected by the changes in the underlying physical structure of the data
It is a fairly complex software product, and although I am not an RDBMS developer, I will try to provide a high-level architectural overview of some of the RDBMS modules and what the responsibilities of those are.
Each module, or a subsystem we could say, represents a level of abstraction. Certain details may vary from vendor to vendor but the concept and the idea are rather the same.
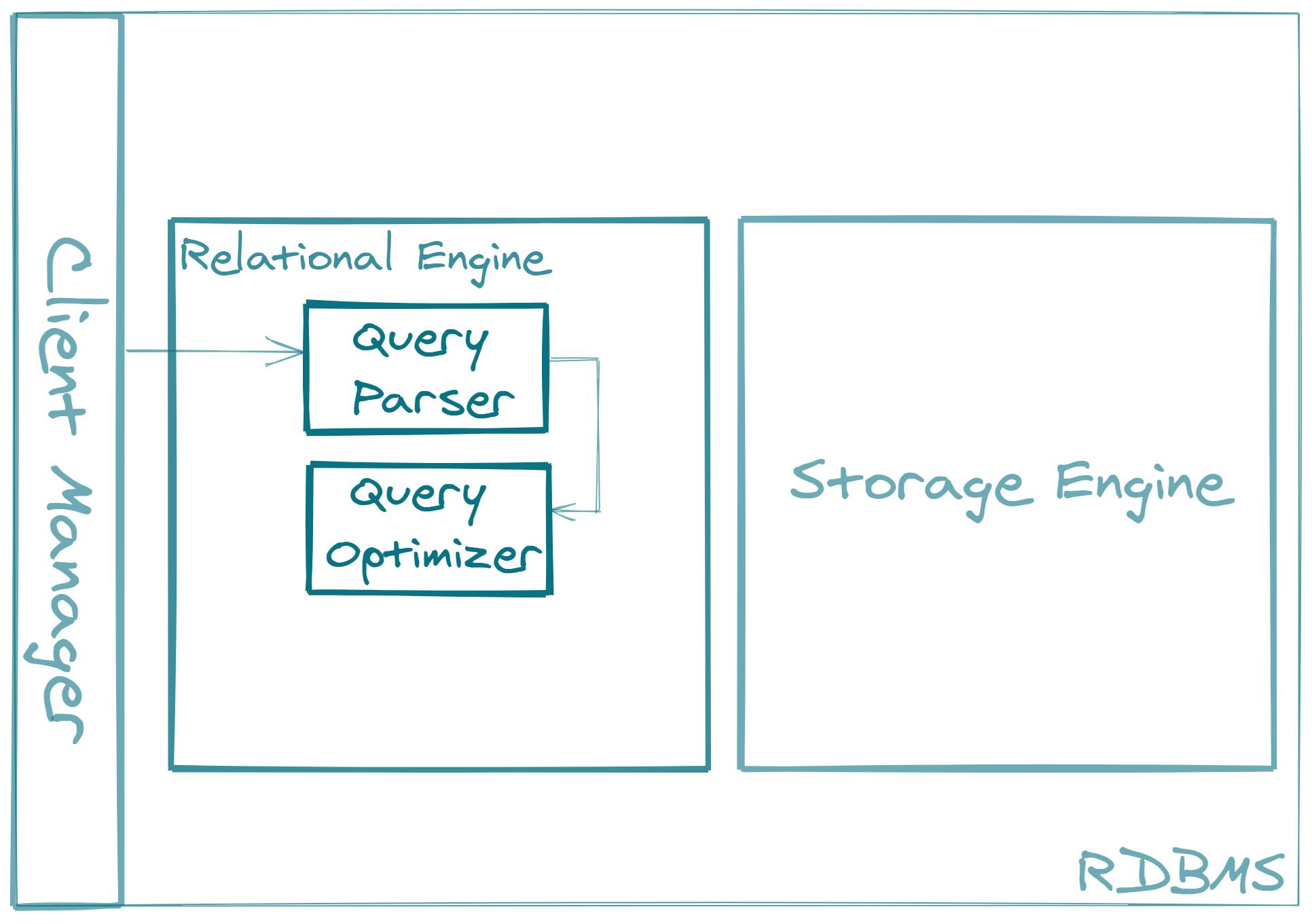
Let us take the highest level overview in which we can identify three key modules.
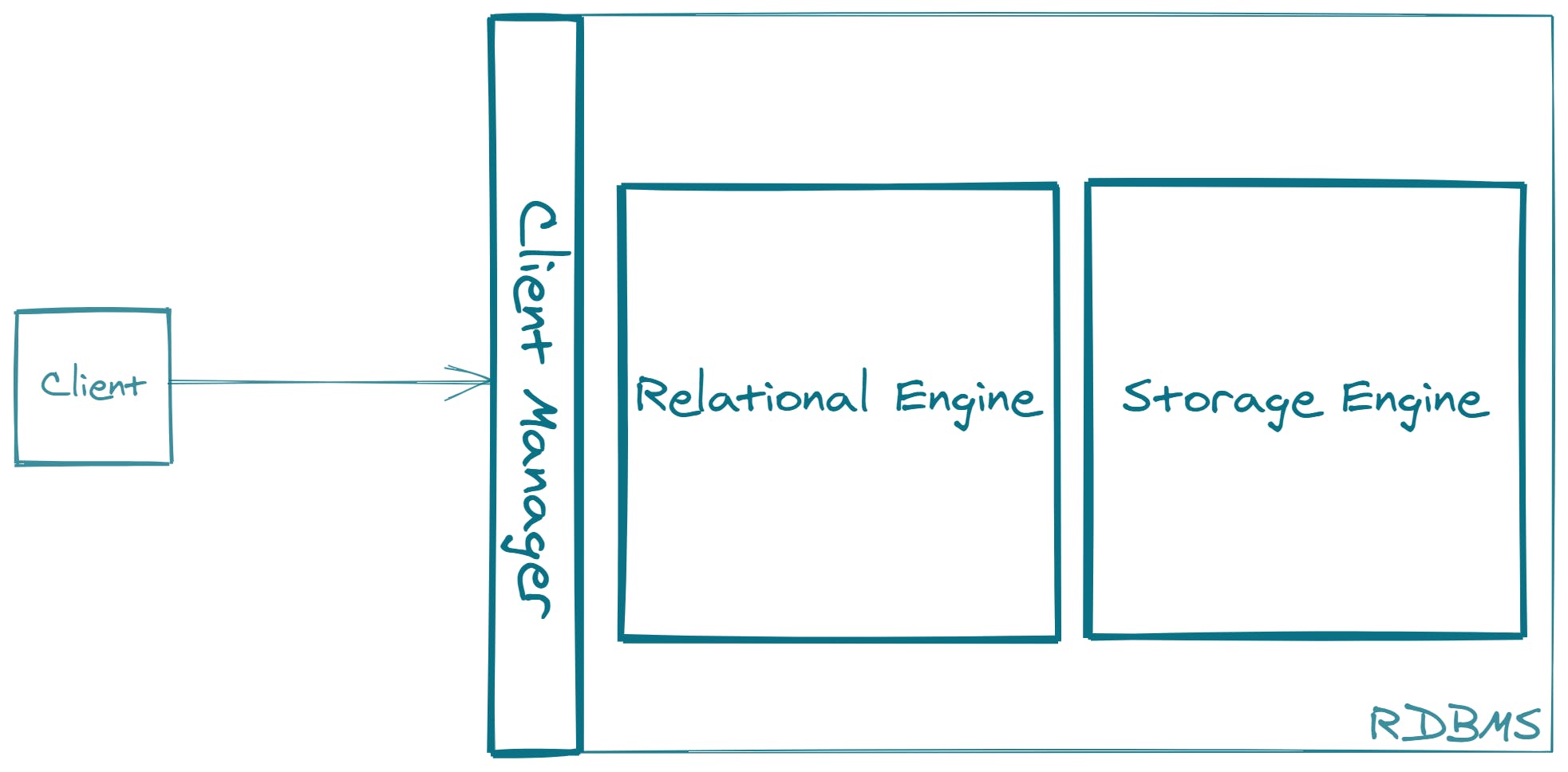
The three modules identified are:
- Client manager
- Relational engine
- Storage engine
First of all, a client sends a request for data as an SQL query.
The client can be software such as SQL Server Management Studio, MySQL Workbench, pgAdmin, or similar.
The client is also, more often than not, an application developed by ourselves, or at least a layer of that application, that that uses a technology such as ADO.NET, JDBC, ODBC, or similar.
Client manager module is responsible for accepting the data request from the client, establishing the connection for that particular client, and eventually returning the requested data, or any errors that occur, to the client. The client manager basically acts as a network interface.
Relational database management systems are commonly implemented as servers and the network protocol that they use is TCP. Regarding the application protocol, different vendors use different application protocols that are built upon TCP. An example would be the Tabular Data Stream (TDS) protocol which is specific to Microsoft SQL Server.
The client manager passes the SQL query further to the relational engine.
The relational engine is the mathematician module.
It consists of different submodules and components that are responsible for parsing the query, validating it, optimizing it, and compiling it into a certain lower-level form.
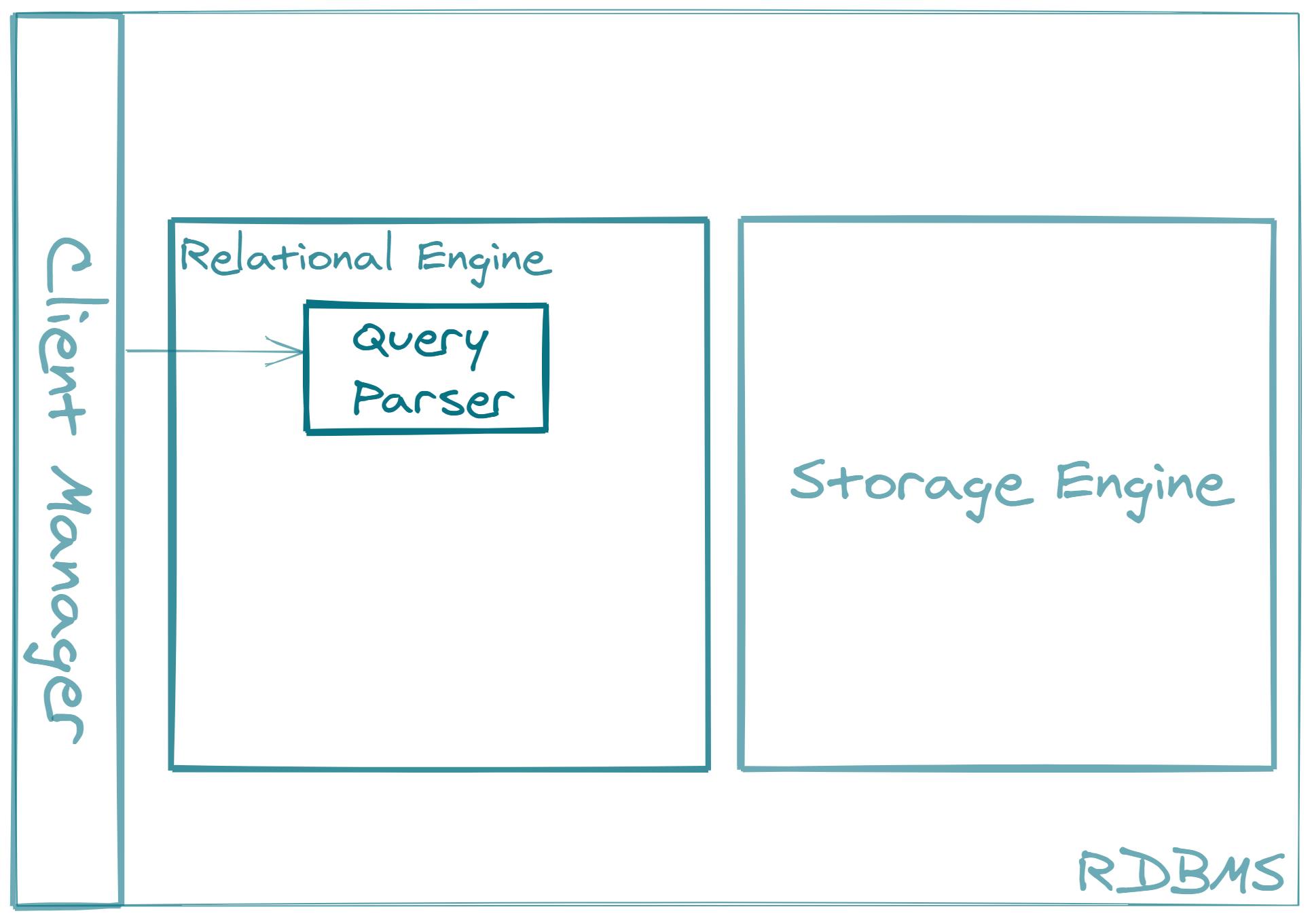
The query parser component is responsible for performing syntactical and semantical analysis and validation, and parsing the SQL query into a structure which is commonly called a query tree.
Syntactical validation is pretty self-explanatory, it checks whether the SQL syntax is correct.
An example of semantical validation would be to check if we used GROUP BY clause and included a column that was not listed in the SELECT clause.
Each node of the query tree structure represents a logical step, a relational algebra operator, that will eventually be executed in order to access the data.
The query tree is then passed to, what usually is the most complex component of an RDBMS, the query optimizer.
The query optimizer goes through certain computation phases, depending on the complexity of the SQL query. During these phases, it attempts to figure out the optimal way for accessing the data.
The result is a so-called execution plan which, at this point, contains a set of:
- Logical operators
- Physical operators
Logical operators are essentially relational algebra operators such as selection, projection, joins, or similar.
Physical operators are, we could say, the implementation of logical operators and they instruct what needs to be done in order to actually perform the selection, projection, or joins, and to access the data on the permanent storage.
So if we, for example, have a logical operator that represents selection, that logical operator can be associated with different physical operators which will represent the implementation of the selection on a physical level.
In our case of selection, the query optimizer can choose the appropriate physical operator such as full table scan, index scan, or index seek.
The choice that the query optimizer makes is based on certain database statistics and knowledge about the physical data organization which it can get from the system catalog. The system catalog acts as an internal database for RDBMS and it stores different metadata.
The following is a very naive example.
Imagine that you are standing in front of a closed door. Your brain tells you to open the door. Now, depending on the circumstances you can open the door in different ways. You can open the door with a hand. Or perhaps your hands are full so you might open in with your elbow. Or you can somehow, and for whatever the reason might be, open the door with your leg.
The concept of opening the door can be realized in multiple ways. It might take you longer to open the door this way or another but in the end, the door is open.
Note that the query optimizer attempts to find the optimal execution plan and not the best possible one. The reason for this is that this process is complex and that the computation time of the algorithms that would attempt to find the best possible execution plan could end up being high, thus the performance would suffer.
Certain RDBMS vendors use the approach for finding the optimal execution plan where they roughly say something like:
Give me the best execution plan, but the one that you find in X units of time, do not go beyond X.
Once the execution plan is created, it is then passed to the query plan executor component.
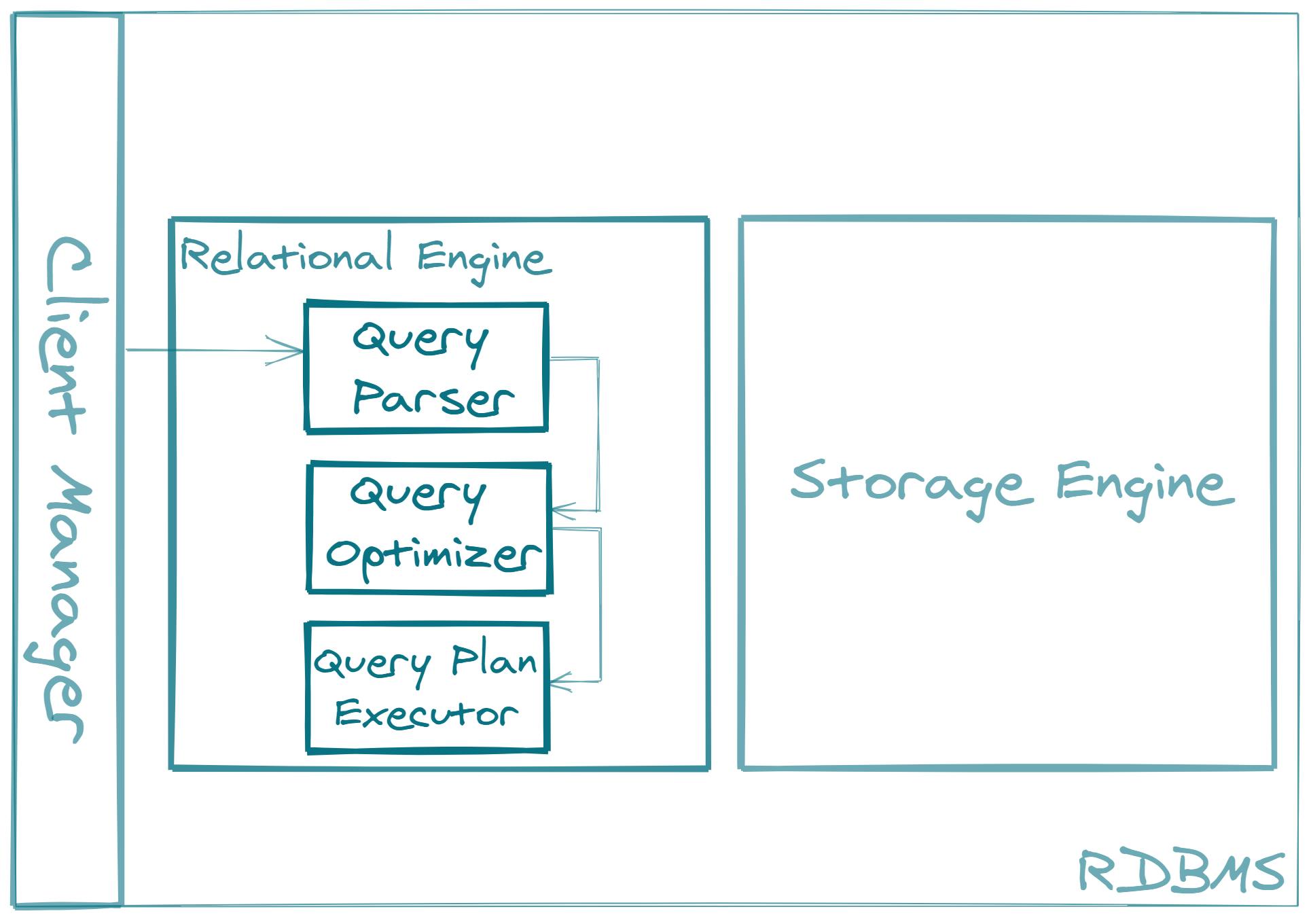
The query plan executor component will handle the orchestration of the execution by passing it to and engaging the storage engine where the physical work will happen, and by eventually collecting the results of the execution.
In part two of this article, we will provide an overview of what happens in the storage engine.